 You may already know it, 20 years ago the HTTP protocol was invented by Tim Berners-Lee and the very first website went online. If you are not so familiar with geek stuff, you may ask now: Does that mean the internet was invented then?
You may already know it, 20 years ago the HTTP protocol was invented by Tim Berners-Lee and the very first website went online. If you are not so familiar with geek stuff, you may ask now: Does that mean the internet was invented then?
HTTP: One Protocol Amongst Many!
TBL, short for Tim Berners-Lee (look him up here if you don’t know him), invented the HTTP protocol. The internet was invented years before that!
To understand what HTTP is, let’s take a look at some protocols required for communication (that are commonly used on the internet for other activities):
- POP (the email protocol)
- FTP (file transfers)
- SSL (security for websites, short for Secure Socket Layer)
- HTTP (for websites, short for Hyper Text Transfer Protocol, also see Hyperlink)
- SSH
- Telnet
- SFTP
- … and so on
As you can see, the protocol for websites is only one of many protocols that people use on a daily basis.
As you can imagine all of the protocols above require a so called “transport layer” in order to send data. POP (emails) for example usually uses a so called “TCP layer” to send data over the internet, but special apps might also use “UDP” to send emails over encrypted SSL connections. You will frequently find those terms in your router configuration, so it makes sense to look them up and understand them if you don’t want to be clueless the next time you open your router config
Whenever you connect to a website it processes a GET request!
The HTTP protocol allows users connected to the network to make certain requests. Once you connect to a website like windows7themes.net you make a series of requests on every page load. Most commonly:
- GET / POST requests (GET is receiving data / text from sites and POST is used whenever you post a comment or on a forum for example)
- HEAD (if you don’t want to retrieve a complete page and only need information about the structure a HEAD request is usually sufficient)
- PUT, DELETE, TRACE
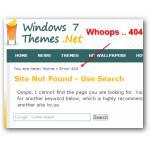
Webservers hosting sites will send out a response (most popular: 404)
Depending on your request, a webserver hosting a website responds to your request. You may know the dreaded 404 response, but there are others you may now know:
- 200 – site found, all ok
- 301 – this site has been redirected to another (be careful!)
- 304 – nothing has changed since your last request
- 400 – whoops, you made a bad request (syntax?)
- 401 – you need to enter a password to see this site
- 403 – get out of here, you are not allowed on this site
- 500 – the server ran into an internet error, this is NOT a problem on your side, contact the site admin
- …
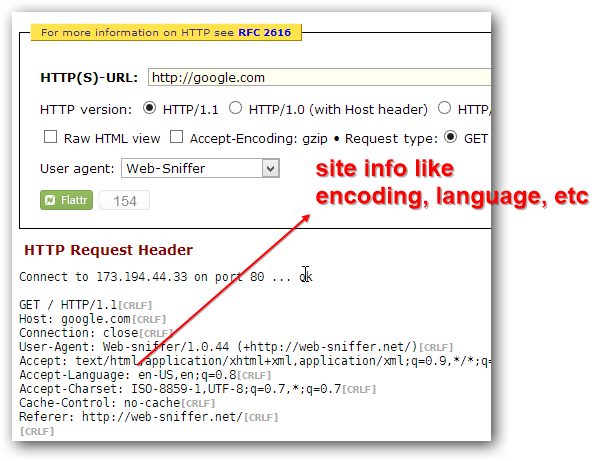
Try web-sniffer.net to get header information to find out more
Head over to web-sniffer.net and enter google.com and hit Enter. You will see that you get quite a lot of information you normally don’t see. This is SOME of the stuff that happens in the background. You can see the character encoding, if the site is using a cache, what programming language the site uses e.g. HTML and lots of other useful info!
I hope this insight is a little interesting for those of you who are not so familiar with servers and internet traffic. I look at daily at server logs and check server responses, you can do that yourself. Try installing XAMPP on your own PC and you will quickly learn a lot about the HTTP protocol!



TBL worked for CERN at the time and CERN republished the first website today:
http://info.cern.ch/hypertext/WWW/TheProject.html
On another sidenote, originally the HTTP protocol was invented to make sharing scientific results easier between various CERN groups